Industrial Automation Repo Map
This note is a deep dive into a curated list of 90 industrial automation repos. Instead of highlighting individual tools, it treats the list as a market map: where activity clusters, which projects look load-bearing, and where maintenance or adoption risk hides.
The space is noisy and weirdly cyclical. Every few years someone "rediscovers" open PLCs (programmable logic controllers), SCADA (supervisory control and data acquisition)-in-a-browser, protocol gateways, and IDE (integrated development environment) tooling. Most of it is hobby-grade. Some of it is quietly becoming infrastructure. The hard part is knowing which is which before you commit to a dependency.
This map works better as a dataset than as a vibes folder.
Quick Take
This map reads active but uneven: 90 repos total, 68 active in the last 12 months, 22 stale and archived, and 19 above the popularity threshold. The data suggests value is not concentrated in new runtimes; it is concentrated where teams can deploy and operate reliably.
Durability still sits in substrate projects like libmodbus, open62541, and mosquitto, while distribution sits in gateway/agent layers like telegraf (16.7k) and dgiot (5.0k). Contribution density supports this: workflow/tooling has 13 repos vs 4 for soft programmable
logic controller (PLC) runtimes.
Open OT (operational technology) is compounding at the edges (protocol + gateway + tooling), while major vendors remain perimeter-open and core-closed. This map is star-biased, and AI (artificial intelligence) is now increasing repo creation faster than maintainership depth, so repo count alone is a weak quality signal. Overall confidence is medium-high on direction, lower on long-tail coverage.
Dataset Overview
Snapshot date: 27 Feb 2026.
Core snapshot metrics are below. Freshness uses a 12-month push window; "Popular" means at least 1,000 stars or 500 forks.
24% stale is not alarming for a niche list. Industrial automation moves slowly by design. A protocol library that hit 1.0 in 2018 and has not been touched since may still be exactly what you need. The question is whether the stale repos are "done" or "abandoned". The archive section is the latter. For the active 68, freshness is a useful but imperfect signal: a burst of activity can mean a real release or just someone cleaning up issues.
List Composition by Bucket
Buckets mix framework/tooling groups with protocol groups (for example Modbus, OPC UA, and EtherCAT are protocol buckets). Overall mix is still more tooling/plumbing than control runtimes.
Bucket Concentration (Top Buckets)
Star Distribution
This is not a list of household names. It is a niche-tool map with a fat tail, and it is star-biased by construction, so many low-star projects are likely missing or underrepresented.
Star Band Distribution
Language Mix (Primary)
The primary language distribution is a decent proxy for where the work actually sits.
Primary Language Mix
Translation: the glue is still .NET and Python; the protocol stacks are still C/C++.
Rust at 4 repos is worth watching. Not because Rust will replace C in field devices anytime soon (it will not), but because newer gateway and tooling work is starting there deliberately. The choice signals something about maintainer culture: people who pick Rust for this work tend to care about correctness in a way that matters when the thing you are connecting to runs a turbine.
TypeScript at 9 tells you the browser-facing layer is real. VS Code extensions, SCADA web UIs, edge dashboards. The OT/IT boundary is not a wall anymore; it is a gradient, and the TypeScript repos are sitting right on it.
What Gets Real Adoption
The top by stars is mostly infrastructure, not "apps". No surprises.
Top repos by stars (selected):
influxdata/telegraf(16.7k stars, 5.7k forks): arguably not an industrial automation project by itself, but critical adjacent infrastructure; the agent layer is a distribution channel.eclipse-mosquitto/mosquitto(10.7k, 2.6k): MQTT remains the default pipe.dgiot/dgiot(5.0k, 1.1k): a very real edge platform, with a China-first focus.frangoteam/FUXA(4.1k, 1.2k): SCADA/human-machine interface (HMI) in the browser, broadly useful.stephane/libmodbus(4.1k, 1.9k): canonical Modbus in C.open62541/open62541(3.0k, 1.4k): OPC UA baseline.
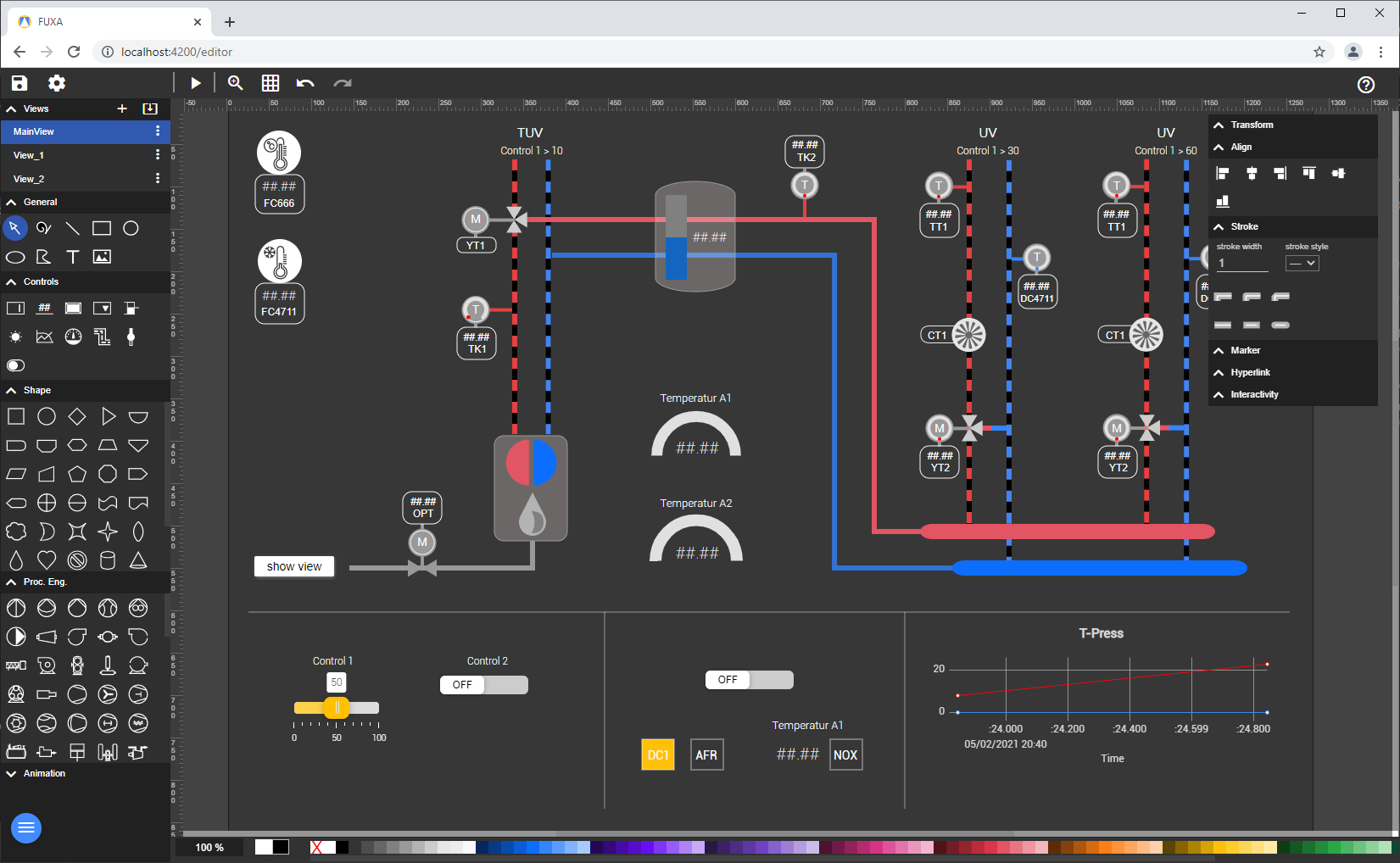
Competing with these repos is not just "building an integration". It means competing with incumbent open-source gravity that already has distribution and operating history.
Also note the mix: agent/gateway projects lead in visibility, but protocol libraries (libmodbus, open62541) remain the long-lived substrate. Both layers matter; one captures distribution, the
other captures durability.
The star counts also reveal where the developer-facing interface is. Telegraf and Mosquitto get stars from backend engineers and DevOps people who have never touched a PLC. That cross-pollination is structural. Once your industrial data is in InfluxDB or flowing over MQTT, the toolchain from there is indistinguishable from any other time-series or messaging problem. That is a feature. It means the talent pool for operating these systems is far larger than the OT headcount would suggest.
The absence of CODESYS, Beckhoff TwinCAT, and Rockwell Studio 5000 from this list is intentional: they are commercial and not open source. But their gravity shapes everything here. Most of the "developer experience" repos exist because those vendors' tooling is expensive, locked-in, or both.
Where Maintenance Load Sits
The repos with the most open issues are the ones that matter operationally. They are not "badly run". They are used.
Top open-issue counts (selected):
open62541/open62541: 883eclipse-mosquitto/mosquitto: 721influxdata/telegraf: 452frangoteam/FUXA: 360
Maintainer bandwidth and issue-triage patterns are part of the downstream supply-chain risk profile for teams depending on these projects.
883 open issues on open62541 sounds alarming. It is not. It is a sign that the project is load-bearing for a lot of real
deployments across multiple industries and countries, many of which have divergent edge cases.
The issue queue is the project's surface area made visible. Compare it to a project with 12
stars and 0 issues: the latter is not healthier; it is just unknown.
What would worry me is a project with high star count, high issue count, and a commit history that shows one or two people doing all the work with no sign of succession planning. That is a supply chain risk in the real sense. FUXA at 360 open issues with a small maintainer team is worth watching on that axis.
Developer UX Is Converging
One strong pattern in the list is migration of PLC developer workflows into mainstream tooling, with VS Code currently the most visible centre of gravity.
This does not mean ST (Structured Text) replaces ladder. In production plants, language choice is constrained by who supports the line at 2am, what IDE/runtime the vendor ships, and what licences the site actually owns.
Two camps show up:
- Syntax coverage: highlights, snippets, outline, formatter-lite. This spreads fast.
- IDE-grade language intelligence (language server protocol, LSP): diagnostics, indexing, rename, quick fixes, formatting discipline. This is what teams pay for once a codebase exists.
The practical read: editor distribution matters, but protocol reliability, device support, and deployment operations still decide production adoption.
The pattern is consistent across the list: teams do not want a new IDE, they want the editor they already use (VS Code) to handle Structured Text with modern language tooling. Diagnostics on save, go-to-definition, reliable rename, and deterministic formatting are table stakes in mainstream software and still uneven in industrial workflows.
A durable pattern is mixed-language architecture: ladder/FBD for high-visibility interlocks and troubleshooting paths, ST for calculations, arrays, algorithms, and reusable blocks. That blend matches how most teams actually maintain systems.
The two-camp split (syntax coverage vs. LSP) is also a business model split. Syntax coverage spreads fast; LSP can monetize once teams have real codebases. But neither wins alone without credible integration into runtime, testing, and change-management workflows.
Siemens: Perimeter Strategy In Public
The Siemens repos in the list are mostly "around the PLC", not "the PLC":
- Engineering automation examples (
tia-portal-openness-code-snippets). - Edge debugging (
edgeshark). - BSPs (
meta-iot2050). - A design system (
ix). - Webserver application programming interface (API) clients for S7.
This is a perimeter strategy: open enough to make the ecosystem productive, keep the core runtime and lifecycle tooling behind the wall.
This pattern is less "Siemens is going open" and more "Siemens is making integration cheaper". Useful for ecosystem velocity, still a perimeter strategy.
The design system (ix) is the most interesting item in this cluster. It is Siemens betting that the UI layer
for industrial applications converges toward the same component patterns as enterprise
SaaS, just with more status indicators and fewer marketing gradients. They are probably
right. The teams building HMI and SCADA replacements do not want to design a button
component from scratch; they want something that looks like it belongs in a control room
without requiring a UX consultant to approve it.
The perimeter strategy also means Siemens is not going to kill the open source ecosystem for TIA Portal tooling. They will tolerate and occasionally enable it, because every automation engineer who can script against TIA Portal via Openness is more productive and less likely to switch vendors. Lock-in through productivity, not walls.
Big Vendor Plays and Gaps
A visible gap in this map is first-party open-source depth from major PLC/distributed control system (DCS) vendors, especially Schneider Electric, Rockwell, Emerson, Honeywell, and ABB core runtime stacks.
That gap is structural, not accidental. Core control runtimes sit inside revenue and risk-bearing layers: licensed engineering suites, hardware margins, validated function libraries, support contracts, and certification/compliance obligations. Open sourcing those layers weakens moat and complicates liability boundaries.
What tends to be open are perimeter assets: application programming interfaces (APIs), software development kits (SDKs), edge adapters, examples, or UI components. This creates ecosystem productivity without surrendering lifecycle control of the core runtime.
In practice, this is why there is no broad open equivalent of "SE core control stack" in the repo landscape despite large installed base. Open innovation clusters around integration friction, not around incumbent runtime internals.
OpenPLC: Still The Reference Spine
thiagoralves/* shows up a lot, and much of it is old. It still matters because
it anchored how people talk about "open PLC":
- A v3 runtime stack people have actually used in research and training.
- Enough ecosystem glue (editor, web UI, hardware experiments) to create a narrative.
There is now a newer split architecture from Autonomy Logic: Autonomy-Logic/openplc-editor (v4 desktop IDE) plus Autonomy-Logic/openplc-runtime (v4 headless runtime with REST/WebSocket). That differs from the older v3 model that bundled
more of the workflow into one path.

The lesson is not "copy OpenPLC". The lesson is that narrative plus an end-to-end path (even if imperfect) beats a pure library.
The deeper lesson from OpenPLC's staleness is the maintenance contract implicit in open-source runtimes. Determinism, scan-cycle guarantees, and hardware input/output (I/O) support are hard but solvable; long-horizon maintenance is the harder constraint. Once deployed in real facilities, the key question becomes maintainership continuity over multi-year horizons.
Licence Reality: Metadata Lies
GitHub's licence metadata is messy. A non-trivial number of repos show "no licence" in the API while still being mainstream open source.
Example: eclipse-mosquitto/mosquitto shows as NONE via the API in the snapshot, despite being a foundational Eclipse
project.
For commercial diligence, licence checks operate as a real workflow:
- read the actual
LICENSEfile, - check for dual-licensing,
- check for copyleft components in the dependency chain.
Copyleft examples in this map include thiagoralves/OpenPLC_v3 and beremiz/beremiz (both GPL-3.0).
A recurring pattern in industrial procurement is that copyleft exposure in dependency chains becomes visible late, usually during legal review. In this segment, gateway/edge products that include GPL protocol components (including transitive pulls) often face slower approval cycles or scope reduction once compliance teams map firmware obligations. The practical effect is commercial friction that is usually invisible in stars, forks, and issue counts.
What Data Suggests to Build
Build where pain is constant and budgets exist:
- Protocol and gateway reliability layers (reconnect behaviour, buffering, retries, backpressure, telemetry) with predictable ops behaviour.
- Structured Text quality tooling that works cross-vendor (formatter, lints, refactors, guidelines, CI integration), increasingly important as AI accelerates code generation.
- Test and verification workflows that fit real teams (not "formal methods theatre").
- Asset and change observability for OT environments (inventory drift, firmware/version lineage, signed rollout history, audit exports).
Lower-confidence build targets in this snapshot:
- New PLC runtimes without a serious plan for IO, determinism, and support.
- Security tooling with unclear licensing and no maintenance. Great demos, bad dependencies.
The "operationally boring gateway" point deserves emphasis. Gateways that cannot preserve config across power cycles, support safe rollback, or expose remote telemetry turn into high recurring ops cost. That cost rarely appears in stars or forks. The market for "gateway that works at 3am" is real and still underserved in open source.
Cross-vendor Structured Text quality tooling remains high leverage. Teams with mixed CODESYS, TwinCAT, Siemens, and Allen-Bradley footprints face dialect drift, inconsistent tooling, weak linting, and limited CI integration. Repos that close this gap compound value faster than projects that add another runtime.
AI Coding Agents in OT
AI coding agents are starting to change automation workflows, mostly in engineering throughput and documentation quality, not in autonomous plant control.
A visible side effect in the repo landscape is faster hobby-project velocity. Small edge/protocol utilities that previously took days of focused work can now be assembled in hours, increasing total project count even when long-term maintenance capacity does not scale at the same rate.
There is upside too: strong prototypes now appear faster, and some quickly-built projects are already good enough to become real operator tools once maintainership and validation catch up.
The Opcilloscope example in this note fits that pattern: rapid initial build, then iterative hardening toward production-grade utility.

Language dynamics matter: agents are stronger in text-heavy environments, so ST and structured project files benefit faster than proprietary binary project formats. This is another reason plain-text source, command-line interface (CLI) tooling, and open docs are leverage multipliers.
Near-term winning pattern is "agent + engineer + simulator": agent drafts, engineer reviews, simulator validates, then controlled rollout. Teams skipping the middle two steps are taking unpriced operational risk.
Interpretation caveat for this map: growth in repository count increasingly mixes genuine platform progress with AI-accelerated prototypes. Repo volume alone is therefore a weaker signal than maintenance depth, issue handling, and deployment evidence.
Method Notes
All numbers come from the GitHub API as of 27 Feb 2026.
- Freshness is based on
pushed_at. - "Popular" is based on stars/forks at snapshot time.
- Selection is star-biased, so low-star repos are underrepresented in this map.
- Language is GitHub's primary language field.
- Licence is GitHub's API metadata, which is not reliable enough to use as a compliance source.
Framing was cross-checked against practitioner discussions and vendor-ecosystem comparisons. Direction stayed consistent:
- Language choice is context-dependent; there is no universal winner.
- Ladder remains common for plant-floor troubleshooting and ownership handoff.
- ST is high leverage for algorithms, reusable logic, and data-heavy workflows.
- DevOps readiness depends on more than language: plain-text source, CLI, Linux tooling, testing, licensing clarity, and docs access.